AI到底是怎么变聪明的?——从数学原理到训练你自己的聊天机器人
2019年你在网上跟AI聊天,它会跟你说「对不起,我不太理解你的问题」。
2023年你再跟AI聊天,它帮你写代码、翻译文言文、解释量子力学,甚至能帮你分析你跟前任到底哪里出了问题。
从「人工智障」到「你仿佛在跟一个真人在对话」,前后只差了大约四年。发生了什么?
先说答案:不是AI突然「觉醒」了,而是人类终于找到了一种让AI「读」完整个互联网的方法。
回归本质:AI到底是什么
不管ChatGPT看起来多邪乎,它的本质非常朴素:它是一个「下一个词预测器」。
你给它「今天天气真」,它猜下一个字是「好」。你给它「1+1=」,它猜「2」。你给它一段Python代码的开头,它猜接下来的代码长什么样。
就这么简单。重复无数次。
你在ChatGPT里问「怎么做红烧肉」,它给你的几百字回答,其实是这样一个过程:
输入「怎么做红烧肉」 → 预测第一个输出字 → 把输出拼回去再预测下一个字 → 再拼回去再预测下一个 → 循环几百次 → 得到完整回答
每一个字都是基于前面所有内容算出来的概率最高选择。
那问题来了:凭什么一个「猜字游戏」能回答物理题、写代码、做翻译?
因为世界上几乎所有能被文本记录的知识,都有规律。物理教科书里的文字有规律,GitHub上的代码有规律,维基百科有规律,甚至知乎吵架都有规律。只要数据量够大、模型够大,这个「猜字游戏」就能学到这些规律。
拿物理举例:训练数据里有成千上万道物理题和答案。模型不会「理解」牛顿定律,但它学会了——当文本中出现「质量2kg的物体受到10N的力,加速度是多少」这种模式时,后面大概率跟着「5 m/s²」。
这不是真正的理解,但这种「统计层面的正确」在绝大多数情况下跟「真正的理解」产生一样的结果。
为什么以前的AI做不到?
GPT-2(2019年)和GPT-4(2023年)用的是同一套底层架构——Transformer。那为什么GPT-2像个傻子,GPT-4像个人?
三个字:大就完了。
OpenAI的研究者发现了一条规律,现在人们叫它Scaling Law(规模定律)——简单说就是:模型参数越多、训练数据越多、算力越大,模型的能力就越强。而且这个增长是可预测的,不是玄学。
给你几个数字感受一下:
| 模型 | 参数量 | 训练数据量 |
|---|---|---|
| GPT-1 (2018) | 1.17亿 | 5GB文本 |
| GPT-2 (2019) | 15亿 | 40GB文本 |
| GPT-3 (2020) | 1750亿 | 570GB文本 |
| GPT-4 (2023) | 未公开(传闻1.8万亿) | 未公开(TB级别) |
参数量从1亿涨到1万亿以上,数据从5GB涨到TB级别。这就是「突然变聪明」的秘密。
更惊人的是,这个过程中出现了涌现能力(Emergence)。有些能力在小模型里完全不存在,但当参数超过某个阈值后突然就出现了。比如:
- 代码生成
- 逻辑推理
- 多语言翻译
- 思维链(Chain-of-Thought)
不是工程师专门为这些能力写了代码,它们是自己「长出来」的。规模跨过临界点,新能力自动涌现。
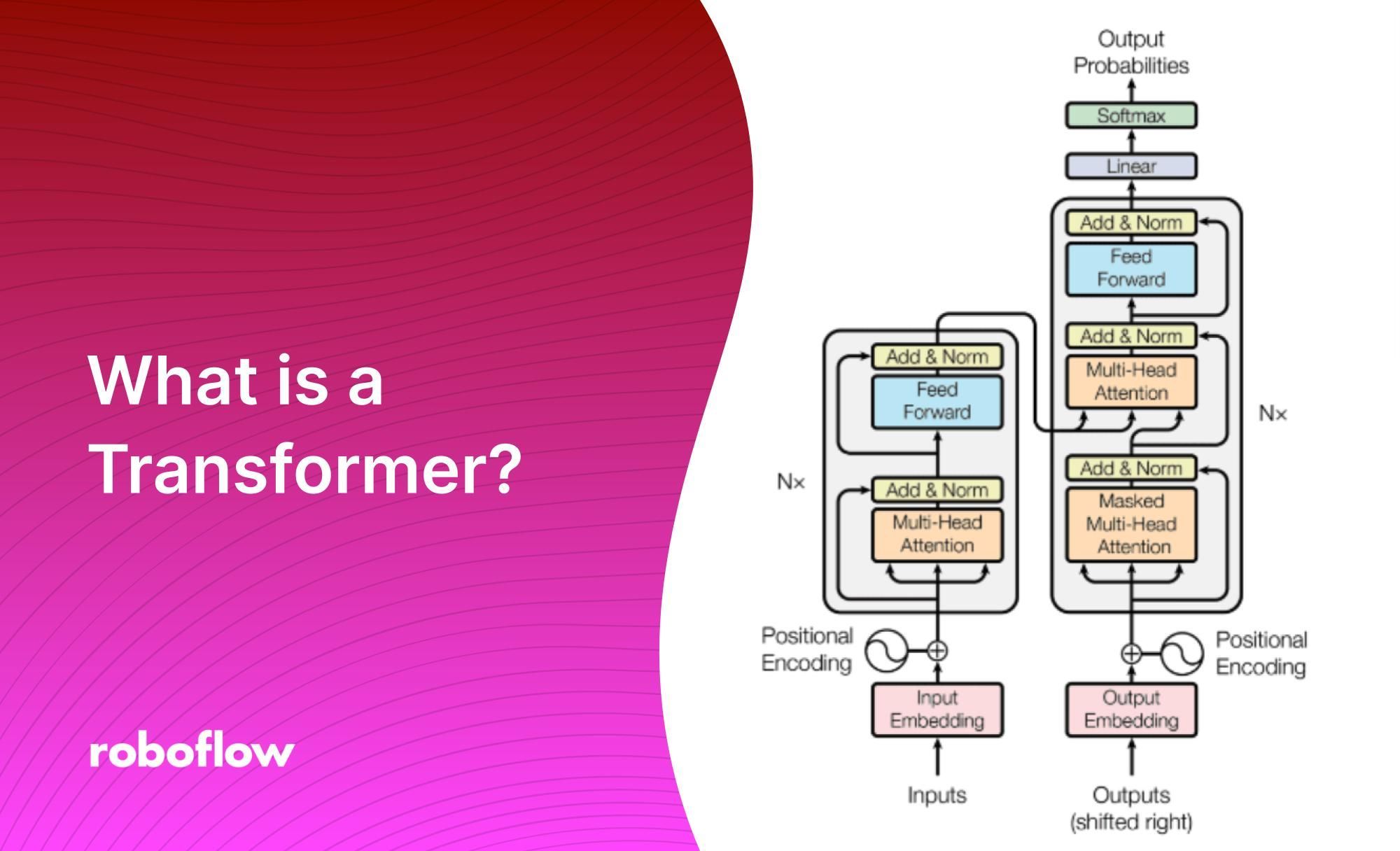
核心引擎:Transformer和自注意力
刚才说「GPT-2和GPT-4用同一套架构」,那这套架构到底是什么?
2017年,Google发表了论文《Attention Is All You Need》,提出了Transformer架构。在此之前,AI处理文字的方式是逐字逐句、按顺序来——读完第一个字才能读第二个字,跟人阅读差不多。这种RNN/LSTM架构有两个致命问题:慢,而且读到后面忘了前面。
Transformer改了一件事:它一次看所有字,然后自己决定哪些字之间有联系。
这叫「自注意力机制(Self-Attention)」。
举个例子。这句话:
「小明把苹果给了小红,她很开心。」
「她」指的是谁?人一看就知道是小红。但AI怎么知道?
自注意力的做法是:把「她」跟句子里每个词都算一遍关联分。跟「小红」的关联分最高,所以「她」=「小红」。
更厉害的是,Transformer不是只做一次——它有多头注意力,从不同角度同时分析。一个头可能关注语法结构,另一个头关注指代关系,还有一个头关注语义。
对一整篇文章,所有词两两之间都算关联。这种全局视角让Transformer对上下文的理解远超以前任何架构。
为什么ChatGPT能聊天:RLHF
规模让模型变聪明了,但聪明不等于听话。一个1750亿参数的GPT-3,你问它「怎么做红烧肉」,它可能回答「第一步,买一头猪」。
它知道很多东西,但它不知道「用户想要什么样的回答」。
OpenAI的解法是RLHF(从人类反馈中强化学习)。
步骤如下:
- 先让GPT-3做预训练,读完整个互联网(这时候它什么都知道,但什么话都敢说)
- 雇人写「好的回答」,用这些数据微调模型(教它什么样的回答是人类喜欢的)
- 让模型生成多个回答,雇人给这些回答打分排序
- 用这些排名训练一个「奖励模型」
- 用强化学习(PPO算法)让模型学会生成奖励模型喜欢的内容
经过RLHF之后,模型开始表现出「有礼貌、有帮助、无害」的特征。不是它自己悟出来的,是被人类用打分教出来的。
用代码理解:一个极简版Transformer
光说不练差点意思。下面这段代码是一个能真正跑起来的微型Transformer,不依赖PyTorch之外的任何库。
import torch
import torch.nn as nn
import math
class MiniAttention(nn.Module):
"""自注意力:让每个词看到所有其他词"""
def __init__(self, d_model=64, n_heads=4):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x):
B, T, D = x.shape
# 计算Q、K、V
Q = self.W_q(x).view(B, T, self.n_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(B, T, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(B, T, self.n_heads, self.d_k).transpose(1, 2)
# 注意力分数:Q和K的点积,越大说明越相关
scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 防止看到未来的词(对于生成任务)
mask = torch.triu(torch.ones(T, T), diagonal=1).bool()
scores.masked_fill_(mask, float('-inf'))
# softmax转成概率
attn = torch.softmax(scores, dim=-1)
# 加权求和
out = (attn @ V).transpose(1, 2).contiguous().view(B, T, D)
return self.W_o(out)
class MiniTransformer(nn.Module):
"""一个能真正训练的最小Transformer"""
def __init__(self, vocab_size=5000, d_model=64, n_heads=4, n_layers=2):
super().__init__()
self.token_embed = nn.Embedding(vocab_size, d_model)
self.pos_embed = nn.Embedding(512, d_model)
self.layers = nn.ModuleList([
nn.TransformerEncoderLayer(d_model, n_heads, dim_feedforward=256,
dropout=0.1, batch_first=True)
for _ in range(n_layers)
])
self.ln = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, vocab_size)
def forward(self, x):
B, T = x.shape
pos = torch.arange(T, device=x.device).unsqueeze(0)
x = self.token_embed(x) + self.pos_embed(pos)
for layer in self.layers:
x = layer(x)
return self.head(self.ln(x))
# 创建一个能跑的模型
model = MiniTransformer(vocab_size=5000)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
# 模拟输入:一批8个句子,每个20个token
fake_input = torch.randint(0, 5000, (8, 20))
output = model(fake_input)
print(f"输入形状: {fake_input.shape} → 输出形状: {output.shape}")
# 输出: 模型参数量: 245,200
# 输入形状: torch.Size([8, 20]) → 输出形状: torch.Size([8, 20, 5000])
# 输出最后一维5000代表每个位置上5000个词的预测概率
上面的模型只有24万个参数(GPT-4有上万亿),但结构逻辑完全一样——嵌入层→多层Transformer→输出头。
把这个结构放大一万倍、几十万倍,用几千张GPU训练几个月,喂给它整个互联网的文本——你就得到了一个能跟你聊天的AI。
如何训练你自己的聊天AI
完整从零训练一个ChatGPT不现实(成本百万美元起步),但你可以做一个能聊天的AI,有两种路径。
路径一:微调开源模型(适合有GPU的人)
HuggingFace上有大量的开源模型可以用:Qwen(通义千问)、LLaMA、Mistral等。你用LoRA(低秩适配)只训练极少参数就能让模型学会新东西:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
import torch
# 加载模型(以Qwen2.5-0.5B为例,普通显卡就能跑)
model_name = "Qwen/Qwen2.5-0.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# LoRA配置:只训练0.1%的参数
lora_config = LoraConfig(
r=8, # 秩,越大效果越好但越慢
lora_alpha=16, # 缩放系数
target_modules=["q_proj", "v_proj"], # 只修改注意力层的Q和V
lora_dropout=0.1,
)
model = get_peft_model(model, lora_config)
print(f"可训练参数: {sum(p.numel() for p in model.parameters() if p.requires_grad):,}")
# 准备你自己的对话数据
# 格式: [{"role": "user", "content": "问题"}, {"role": "assistant", "content": "回答"}]
training_data = [
{"messages": [
{"role": "user", "content": "你是谁"},
{"role": "assistant", "content": "我是小明训练出来的AI助手"}
]},
# ... 更多对话数据
]
# 将数据转成模型能懂的格式
def format_chat(example):
text = tokenizer.apply_chat_template(
example["messages"], tokenize=False
)
return tokenizer(text, truncation=True, max_length=512)
# 然后用Trainer训练即可(完整训练代码略,核心就这些)
路径二:调用API + 知识库(适合所有人)
如果你没有好显卡,用API也能做一个「你自己的AI」:
import json
class MyChatBot:
def __init__(self, your_knowledge_file="my_notes.txt"):
# 读取你自己的知识
with open(your_knowledge_file, "r") as f:
self.knowledge = f.read()
self.history = []
def ask(self, question):
# 系统提示词里注入你的知识
system_prompt = f"""你是小明训练的助手。你有以下知识库:
{self.knowledge}
请基于以上知识回答问题。不知道就说不知道。"""
messages = [{"role": "system", "content": system_prompt}]
messages += self.history[-6:] # 保留最近3轮对话
messages.append({"role": "user", "content": question})
# 调用任意大模型API
response = call_llm_api(messages) # 替换为实际的API调用
self.history.append({"role": "user", "content": question})
self.history.append({"role": "assistant", "content": response})
return response
# 使用
bot = MyChatBot("my_notes.txt")
print(bot.ask("我上次说想学什么来着?"))
本质就是:把你自己的知识塞进系统提示词里,让大模型替你表达。这不算「训练」,但效果在大多数场景下完全够用。
总结:说到底,AI并没有「理解」
写到这里我得坦诚一点。
AI能在99%的场景下给你正确答案,但它没有一个字是「想」出来的——全是从数据和概率里「算」出来的。
你问它「什么是幸福」,它能给你写一篇两千字的论述。但它从来没有感受过快乐。它只是在海量文本里学到了——当「幸福」这个词出现时,后面通常跟着什么样的表达模式。
这和人类的学习有本质区别。你被烫过一次就知道火是危险的,不是因为你在文字里读到了「火的温度很高可能伤害人体组织」一千遍,而是因为你的神经系统真的把「烫→痛→危险」这条线路焊死了。
AI没有痛觉,没有身体,没有欲望。它只是一个空前强大的文本模式匹配器。
但也正是因为这个,它才可怕——即便没有任何感知能力,光靠模式识别和概率计算,就能在几乎所有智力任务上达到甚至超越人类水平。
这意味着什么?意味着人类最引以为傲的「智力」,可能从来没有我们以为的那么神秘。
你问它任何问题,它都能回答——不是因为它懂,而是因为互联网上有人懂过,然后它记住了那个人的表达方式。
这就是现代AI的本质:它是整个人类知识的镜子,反射的是我们所有人的思考方式。


